Math Terms
Mean Squared Error (MSE)
By Vladimir Haltakov
A function that measures how well a predicted value Ŷ matches some ground-truth value Y.
MSE is often used as a loss function for regression problems. For example, estimating the price of an apartment based on its properties.
Detailed formula explanation
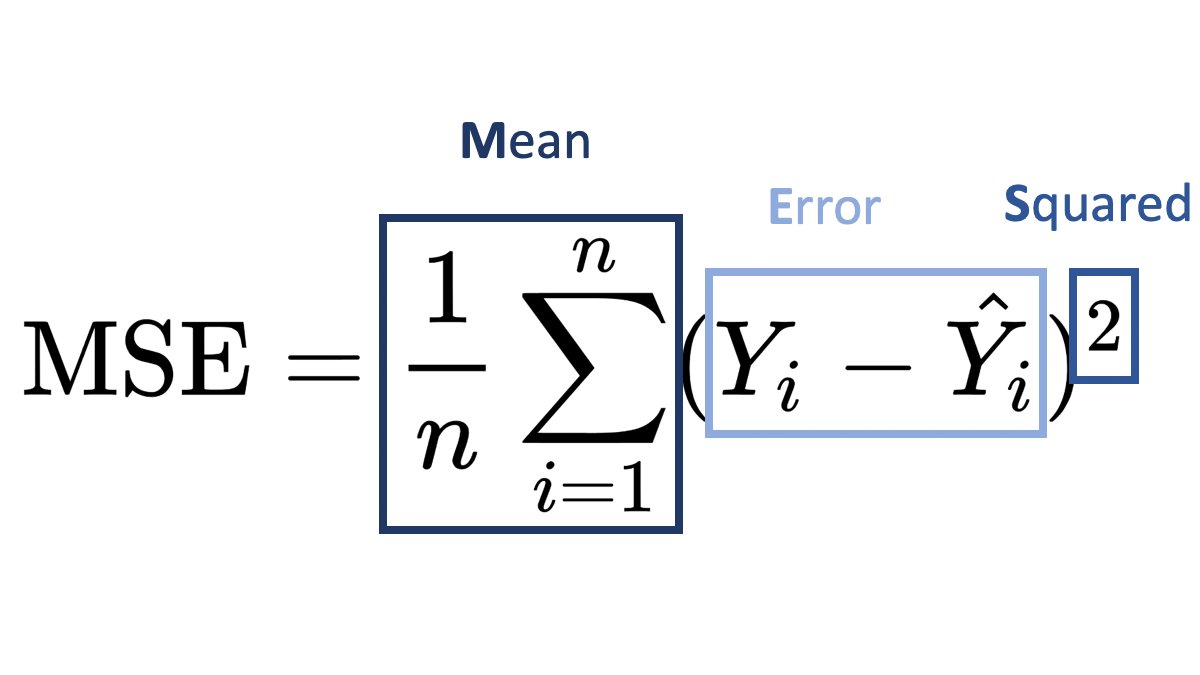
The Mean Squared Error formula can be written as:
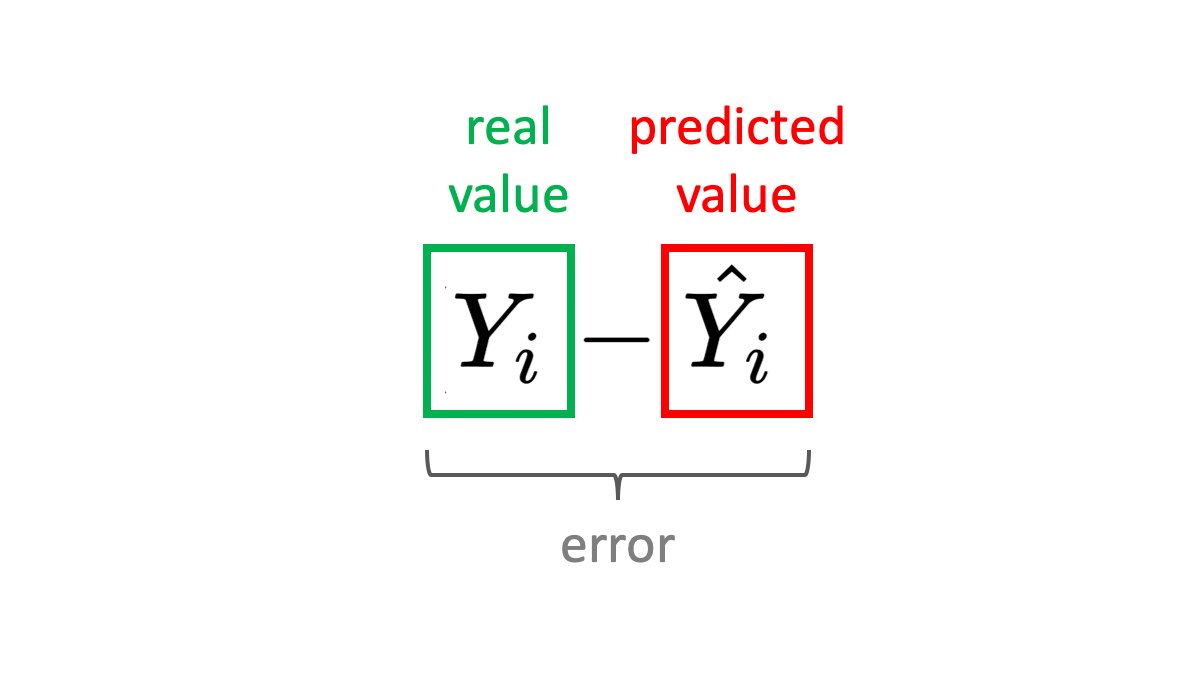
The error is defined as the difference between the predicted value Ŷ and some ground-truth value Y. For example, if you are predicting house prices, the error could be the difference between the predicted and the actual price.
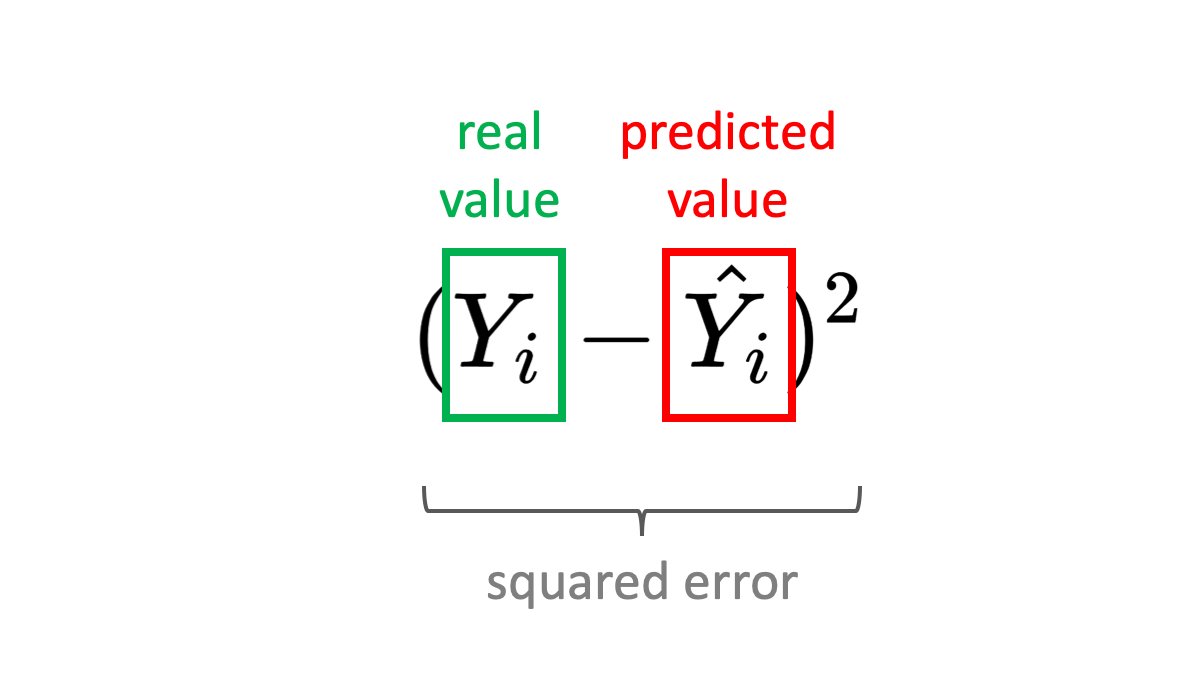
Subtracting the prediction from the label won't work. The error may be negative or positive, which is a problem when summing up samples. Imagine your pediction for the price of two houses is like this:
- House 1: actual 120K, predicted 100K -> error 20K
- House 2: actual 60K, predicted 80K -> error -20K
If you sum these up the error will be 0, which is obviously wrong. To solve this, you can take the absolute value or the square of the error. The square has the property that it punished bigger errors more. Using the absolute value will give us another popular formula - the Mean Absolute Error.
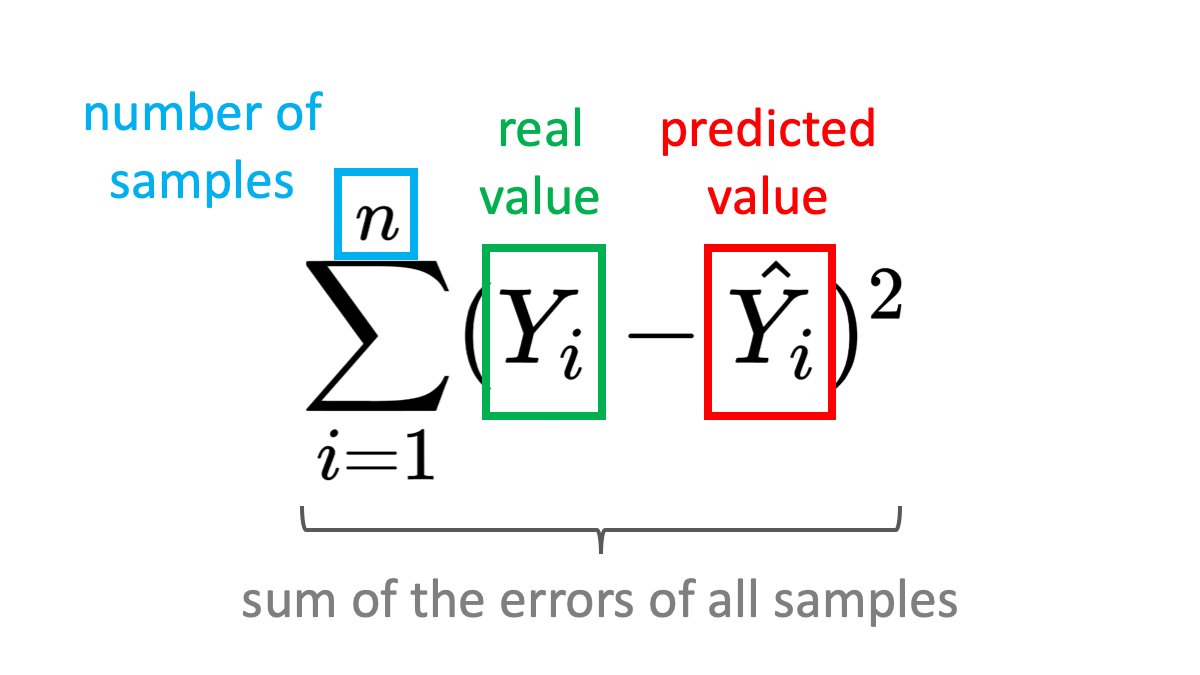
We usually compute the error over multiple samples (in our example - houses). This is a typicall case when training a machine learning model - you will have many samples in your batch. We need to calculate the error for each one and sum it up. Again, having the error be always ≥ 0 is important here.
You are good to go how! However, if you want to compare the errors of batches of different sizes, you need to normalize for the number of samples - you take the average. For example, you may want to see which batch size produces a lower error.
